

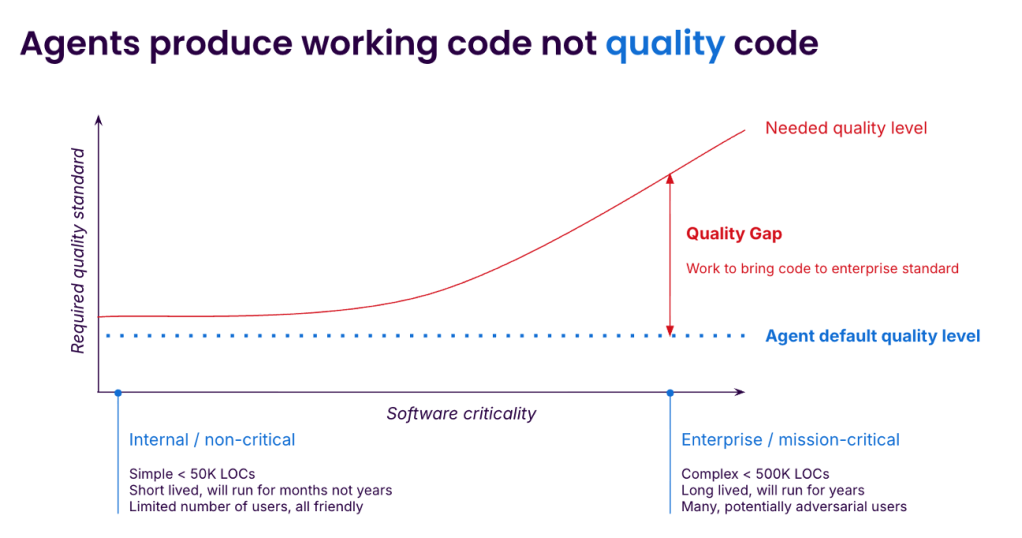
Developers are caught between the joy — or pressure — of using agents to ship 10x faster today and the dread of how they will maintain that code tomorrow. The gap between “vibe” code and code that can be deployed to millions of users is vast and easy to underestimate. Closing the gap requires care, expertise, and effort, with the payoff coming later. Agents are able to complete increasingly complex programming tasks but without the quality we need. What’s missing, and how can we fill the gap?
Sonar
Why agent-generated code degrades: the bloat problem
Enterprise code has to clear three bars: it must be maintainable, reliable, and secure. Out-of-the-box AI agents can miss all three. Let’s focus on the biggest and most visible maintainability issue, which is bloat: redundant validation, defensive checks that cannot fire, near-duplicate functions, dead code that nothing removes. A None check on a parameter typed as dict. A try/except around a call that never throws. Two functions, identical except for the negation in their return statement.
Bloat varies dramatically by model. Sonar’s LLM Leaderboard runs every frontier model through 4,400+ Java tasks and analyses the code generated. To complete the benchmark, GPT-5.4 High generated 1,159,000 lines of code at an 81.05% pass rate, while Claude Opus 4.7 Thinking generated only 336,000 lines of code to return a better than 82.52% pass rate. Different models generate dramatically different code to achieve similar outcomes.